Three thoughts on Tana
On freeform structure, complexity, and data portability.
Tana has taken the PKM community by storm. For good reason. It's still in early release, somewhere between an alpha and a beta version, but it show a lot of potential. I've been using it side by side with Obsidan for the last two months, and think that it soon will be my primary tool for note taking.
The waiting list has been long, and questions about when to expect an invitation are frequent both in the Slack community and on social media. And lately, more new users are onboarded.
I have three thoughts on Tana that might be of interest to new users – and those still waiting for an invite.
Freeform structure
What made Tana click for me is the powerful combination of an outliner like Workflowy and a database like what you can build in Notion, in addition to the Daily Note Pages first made popular by Roam.
The end result is something like "freeform structure". You don't need to think too much about where you enter information in your system, as long as you add metadata about what it is you put into it. The core functionality for this is what Tana calls supertags. In practice, this is a combination of a traditional tag with a database structure: Each supertag has it's unique set of database fields, where you enter the metadata that are relevant for the information you want to have in your system.
This is really one of Tana's best features: Thanks to the fields, you not only have links between different notes, you also have a semantic meaning for the links. This is a link to a person, this is a link to a date, and so on.
And of course, what these database fields are is up to the user to decide. The tools are there – build with them what you need.
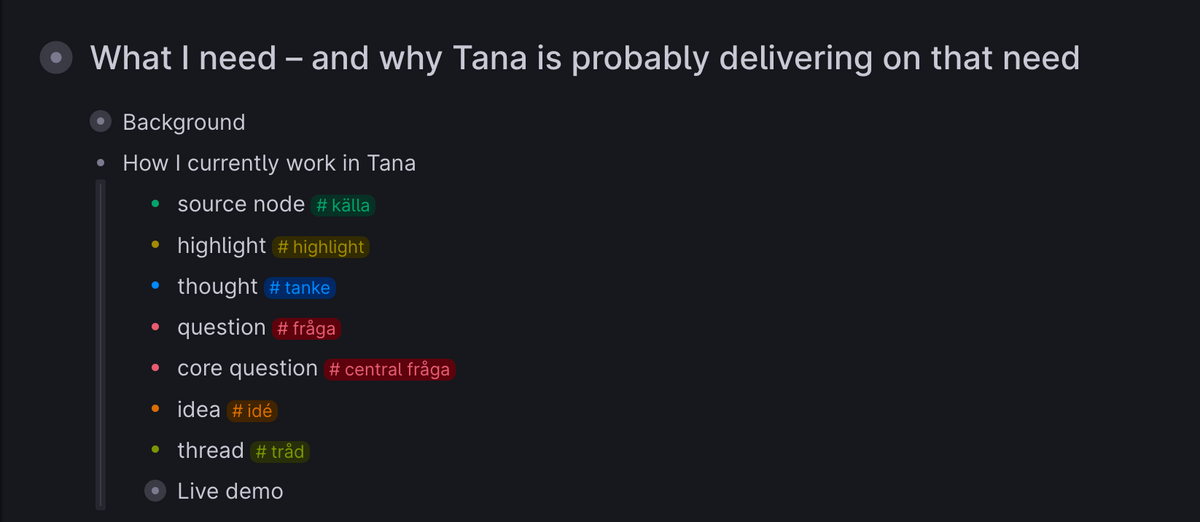
For me, the first take on Tana is creating a system for research notes. With tags for sources, hightlights from the sources, thoughts sparked by the highlights, questions answered in my research, and new article or podcast ideas that are the result of the process, I am starting to create a system much more tailored to my needs than I ever have been able to do before.
Complexity
I understand if this all sounds a bit on the complex side. I often feel the same when I watch tutorials shared in the Tana community. But – and this is important – Tana doesn't have to be complex when you start. Rather the opposite. Begin with a simple system, with the tags that would represent the most central pieces of information to you. It might be #meeting, for meeting notes. #todo, for tasks. #person, for colleagues.
More tags, and fields for them, can be added as you go. To figure out what metadata you need, don't think about it from an input perspective: It's not what you can add about what you write in Tana that's important. It's how you want to find that information later on.
In addition to the supertags, the most important core feature is a very robust search functionality. A bit complex in itself, but steadily becoming for user friends, it makes it possible to assemble the information you need, when you need it.
If I want to see all ideas about technology and democracy, that also would be a great topic for a podcast episode, those notes are just a search away. All todos I need to discuss with a colleague? Define a search. All highlights that relates to artificial intelligence in healthcare and are from conferences I visited the last year? A search finds them.
Data portability
The final thing I want to address is data portability. In a blogpost earlier this year, I argued that it's important to have a exit plan for one's notes, and that local markdown files is the way to go:
But putting my personal research archive in a cloud service, with a proprietary file format, and being forced to trust its export functionality?
No.
Yet, here I am, preparing for making a cloud based service with proprietary file format my primary note taking-tool. How can that be?
For two reason:
Even though the export options currently is limited to a JSON file from Tana, the team has promised that more options are under development. Like Markdown files.
But more importantly, I read a blog post about data ownership in Roam Research. And that turned things on the head for me:
Markdown as a faux standard may lull you into a false sense of security where application-specific extensions do things differently. For example, Obsidian and LogSeq both operate using Markdown as the underlying shared data format, but they each handle and represent block references differently.
Representing the fundamental data structures that Roam uses in a more open and structured interchange format like JSON or EDN makes it easier to move to new tools with more note fidelity since there’s a stricter data structure which can help to transform the data more accurately. Indeed there are already several converters available to take Roam’s JSON into other tools.
And this makes a lot of sense to me. I've used local Markdown files for my notes for close to ten years now. And even if they can all be opened in any text editor, I can really make use of all links between them because the way I've entered metameta data and link style has changed over the years. Instead, it's often via plain text search I can find what I need.
A JSON file from Tana has much more structure to it, making it possible to convert the file to something that could be imported to whatever tool I might want to migrate to in the future. It might not be as easy as it is to point a new text editor to my notes folder on my computer's hard drive, but the end result will probably be more useful.
To me, it seems like the benefits Tana brings to the table, letting me be more productive and extract more value from the information I put into my system, makes this tradeoff worth it.